01 背景与问题
求职主要是重复。每当招聘时,候选人都会重写简历以匹配岗位,重新起草求职信,写一封申请邮件,然后为下一份工作再写一遍。从找到职位到准备提交定制申请的过程缓慢、手动且容易偷工减料,这正是优秀候选人失去动力的地方。
一个常见的答案是自动申请机器人:它会在共享候选人池中,代表用户在招聘网站上自动提交申请。这会牺牲控制量,常常发送那些普通、低质量的申请,而用户从未审阅过。而该平台则持相反立场。雇主没有从候选人池中抽取,平台也不会自动选择职位或发送任何信息。所有操作都运行在一个认证用户的账户内,该用户负责执行哪些任务以及实际发送哪些内容。需要解决的问题既狭窄又真实:去除重复的准备工作,同时不消除申请人的判断力。
02 角色与约束
AI Product Manager我从头到尾掌控了整个产品:从登录到发送应用的工作流程、每代人都被分配的配置文件模型、逐个作业匹配和生成逻辑、信用和变现模型、Gmail草案集成,以及关于AI可做和不能做什么的保护措施。工作很大一部分是确定人工智能应归属的范围。AI负责重复的准备工作,将职位与用户资料匹配,起草简历、求职信和邮件,而人工负责所有重要决策:搜索哪个职位、选择哪些职位、是否生成、包含哪些内容以及是否发送。
这些限制是刻意为之。人为参与是不可妥协的:平台准备 Gmail 草稿,从不自动发送,因此申请人总是审核并点击发送。AI只能使用用户提供或批准的信息;它绝不能虚构资格、工作经历、技能、认证、成就或指标,也不能仅仅为了增加关键词重叠而添加技能。每个用户的数据都严格分开:用户只会触碰自己的个人资料、搜索、选择的职位、生成的文档、 Gmail 草稿、署名和被追踪的应用,绝不会触及他人的。而且因为生成需要运行成本,成本必须透明:用户应该在AI开始前看到动作的信用价格。
03 产品方法
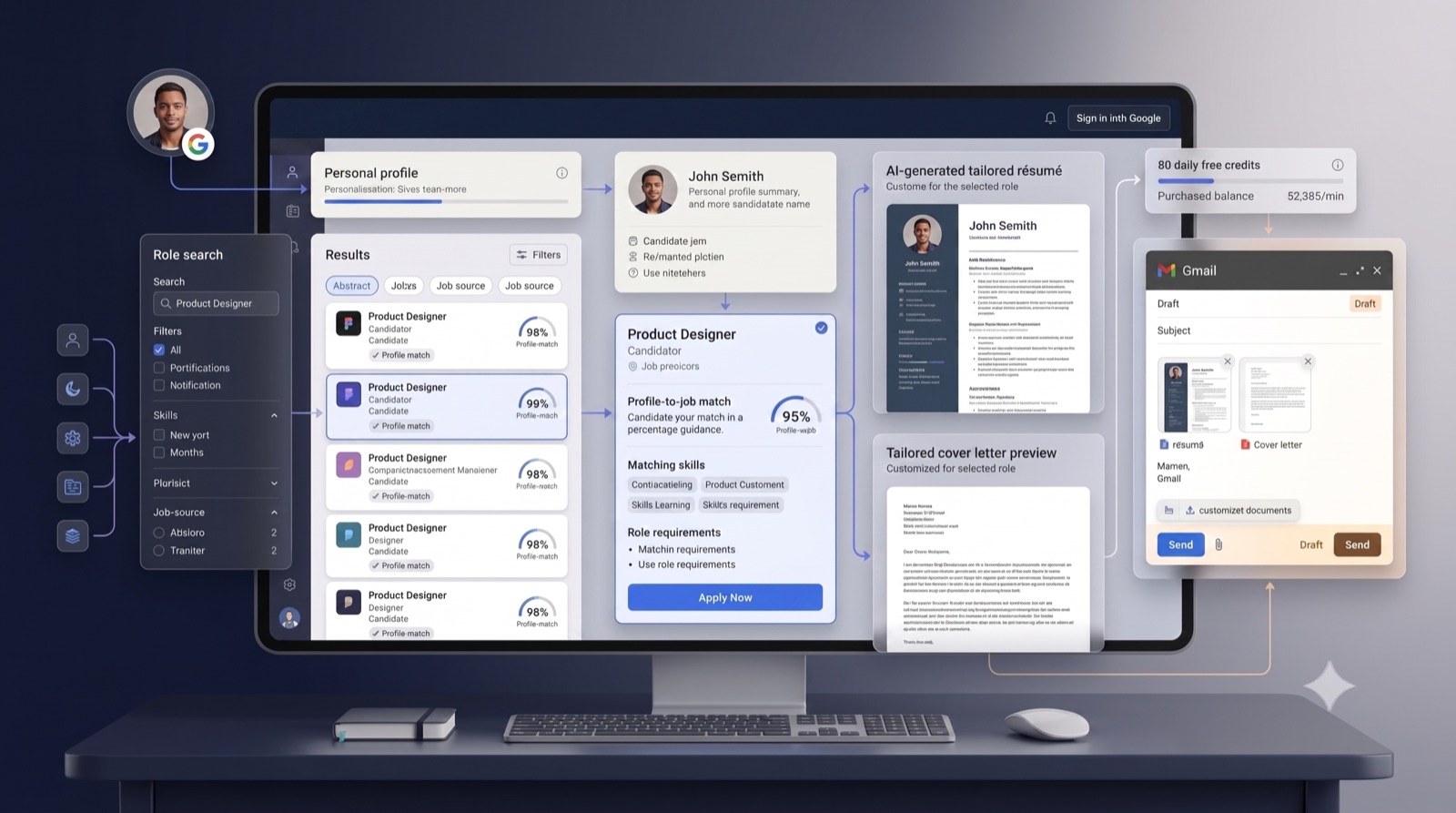
该产品围绕一个认证账户分为两层:免费发现和付费准备。Discovery是免费的,用户可以无阻碍地探索。登录 Google后,用户会建立个人档案、姓名和联系方式、目标职位、专业摘要、经验、教育背景、技能、认证、项目和现有简历,这些简历成为后续所有内容的具体真实信息来源。然后他们搜索职位,平台会从第三方职位门户集成的匹配职位集中汇聚成一个结果集,每个职位会根据该用户的个人资料进行匹配百分比评分,以便优先排序。
准备工作是AI重复性工作的地方,且会计入学分。用户手动选择值得追求的工作,并点击 Apply Now 。对于每个被选中的职位,平台都会生成一个独立的定制化方案:与该职位描述对齐的简历草稿、该职位和雇主的求职信,以及定制的申请邮件,因此同一用户的两份申请可能不同,因为各自针对不同的机会设计。然后它利用用户的 Gmail 集成,整理草稿、职位专题、申请邮箱作为正文,以及附上的简历和求职信,并保存为草稿。它无法发送。用户在 Gmail中打开草稿,查看雇主、职位、收件人、主题、正文和附件,编辑任何内容,然后手动点击发送。一旦发送或标记为已应用,它就会进入该用户的应用追踪器。
生成过程受信用点限制,经济学与价值相匹配:发现保持免费,计算成本高的准备工作是用户付费的。每个用户每天获得免费信用额度,用于尝试或继续工作流程;当它用完后,他们可以购买更多。界面在生成前会显示信用点的费用,用户在调用AI前能了解价格。
大多数职位工具都针对批量优化(自动应用机器人喷洒通用应用)或发现(职位板块会停在列表上)。该平台优化了中间的空白:消除了每份被选职位、简历、求职信和邮件的重复准备,同时保持申请者掌控选择和发送的过程。AI负责绘制;人类保留审判权。
4 个已制造的特色
Google 认证
用户通过 Google 登录创建并访问账户,这也支持 Gmail 草稿工作流程。
用户特定配置文件
结构化的档案(职位、摘要、经验、技能、项目、简历)成为用户唯一的真实信息来源。
基于角色的求职
用户搜索目标角色;该平台汇总了第三方招聘门户的源池中的匹配职位,并且可以添加更多集成。
画像匹配百分比
每个职位都会根据登录用户的个人资料进行评分,按用户和职位进行评分,以帮助优先排序,而非排名候选人。
人工职位选择
用户会查看招聘信息并选择想要追求的职位,点击 Apply Now 开始准备。
per-application résumé
每个被选中的职位都会有自己的简历草稿,与该职位描述相匹配。
申请表求职信
每个职位都会根据职位、雇主和要求单独生成求职信。
按申请发送邮件
每个职位都会准备定制的申请邮件,而不是一封通用邮件,到处重复使用。
Gmail 草案创建
电子邮件、简历和求职信会被整理成 Gmail 草稿。它是保存的,而不是自动发送。
应用跟踪
一旦发送或标记为已应用,该作业会被添加到该用户自己的应用流水线中。
基于信用的发电
AI准备工作以积分为基础:每天免费50点,使用完每日零用时可额外购买。
信用透明度
在任何发电开始前都会显示成本、当前余额、剩余余额和退款行为。
还包括:按用户配置的配置文件作为跨应用可重用的真实信息来源,将不断增长的第三方职位门户集成的源池整合为一个结果集,严格的用户级数据分离,每日免费信用额度及补贴购买流程,以及预生成信用透明度,确保成本在AI运行前即可可见。
05 建筑
一个认证账户就能把所有东西串联起来。单个求职者通过 Google登录,这既验证了他们的身份,也支持后续 Gmail 草稿的工作流程。账户内部运行两条路径:免费发现路径、个人资料加基于角色的搜索,通过第三方职位门户集成的源池搜索,汇总成结果,并根据用户资料进行匹配百分比评分;付费准备路径仅在用户选择职位并点击 Apply Now时开始。
Apply Now流程首先检查信用点。如果余额不足,用户会被引导购买;如果足够,所需的积分将被扣除,并开始生产。AI生成步骤会根据用户的个人资料和所选职位描述,生成三份定制草稿、一份简历、一封求职信和一封申请邮件,这些内容会以单一草稿形式流入用户Gmail,并附带文件。用户审核并编辑草稿,手动点击发送,应用程序会被记录在他们的追踪器中。整个系统贯穿两条设计线:人机参与,即AI草稿,但用户始终发送;以及逐用户隔离,即个人资料、搜索、生成文档、Gmail草稿、署名和跟踪应用归属于一个账户,绝不共享到共同候选人池。堆栈故意保持无聊,使活动部件保持清晰:前端React,后端Node.js,数据Supabase,托管Vercel。源池旨在扩展:每个新的第三方职位门户集成都连接到相同的聚合和评分路径,因此新增门户可以扩大覆盖范围,同时不改变工作流程。
06 变现与制作人员
平台将免费发现与基于信用的应用生成分开,因此变现符合价值:用户可以免费寻找和评估机会,只需为计算密集的准备付费。免费功能包括创建账户、建立个人资料、搜索和汇总职位、查看描述、查看匹配百分比以及选择职位进行考虑。信用点用于AI辅助的工作、简历、求职信和申请邮件生成以及 Gmail 草稿组装,每位用户每天可获得50个免费信用点,以保持工作流程的可用性,然后再购买付费套餐。当每日用完后,用户需补充以继续使用。关键是,成本在生成前就已显示:当前余额、所需信用额度、剩余余额(包含哪些输出)、失败生成的退款行为、每日信用重置时间,以及编辑或再生哪个成本更高,因此用户在调用AI前总能了解价格。结果是采用付费杠杆模式,而非付费发现:用户自由探索,并付费大规模准备。
自由发现层
账户创建、个人资料建设、搜索、聚合、匹配可见性和职位选择,全部无需消费积分。
付费准备层
学分用于简历、求职信和电子邮件生成,以及 Gmail 草稿组装,这些计算密集的工作。
每日免费信用额度
每位用户每天可获得50个免费积分,用于尝试或继续生成流程,然后再购买套餐。
代际前透明度
余额、所需积分、生成后剩余、退款和重置时间都会在AI运行前显示。
补贴购买流程
当每日余额用尽后,用户需额外购买信用额度以继续准备申请。
07 人工智能决策层
AI层一次只为一名认证用户和一个选定的作业工作;它从不将申请者与共享池进行比较。它通过一连串简短的决策来实现。这个职位和用户的匹配度有多高?它将职位描述与登录用户的个人资料进行比较,生成用户特定的匹配百分比,理想情况下还包括说明、匹配技能和经验、职位术语、缺失或未确认的要求、地点和经验水平匹配度。哪些经过验证的信息应该出现在简历中?它从用户自身的个人资料和简历数据中提取相关事实,并仅利用候选人提供的信息,决定哪些对该职位最有用。简历应如何定制?它可以调整摘要措辞、技能排序、经验重点、项目选择、成就排序、术语和章节优先级,而不必仅仅增加关键词重叠。求职信应强调什么,邮件内容应包含哪些内容?它将用户验证的经验与雇主对该职位的要求联系起来,并准备简洁、专业的邮件。世代能否开始?在运行任何账户之前,它会检查信用余额,扣除是否足够,或者引导用户购买。
人工智能会准备;它不决定或捏造。它仅使用用户提供或批准的信息,从不虚构资格、工作经历、技能、认证、成就或指标,也不会为了关键词重叠而在简历上填充技能。它也从不选择职位或发送申请:它会为用户所选职位草拟简历、求职信和 Gmail 邮箱,用户则审核、编辑并点击发送。
08 现状与结果
结果是,每个用户都采用了流程,将求职者从发现阶段转移到一个认证账户内的可审核应用。登录 Google后,用户会在集成渠道中搜索职位,将每个职位与自己的个人资料进行匹配比例比较,并手动选择想要追求的职位。每选中一个职位,平台都会花费信用点生成定制简历、求职信和申请邮件,将其整理成 Gmail 草稿,最终审核和发送完全由用户自行完成。这支持了更高的申请量,同时又不会让体验变成无控制的自动提交:申请者申请更多职位、更快,但每份申请都是他们的,由他们审核和发送。变现方式依然保持着相同的原则:免费发现、每日免费信用额度和为繁重准备付费生成,因此用户支付的价值是重复性工作的杠杆,而非进入就业市场本身。
3
根据所选职位定制文件(简历、求职信、电子邮件)
50
每天每位用户免费获得积分
0
未经用户批准发送的应用
1:1
每个用户、每个职位的匹配分数(从不计候选人排名)
09 反思 / 接下来是什么
现有的建筑承载着核心承诺。可重复使用的每个用户配置文件作为真实信息的来源; Google 每次游戏都有签到门;基于角色的搜索运行在可扩展的第三方招聘门户源池中;每个任务都有每个用户匹配百分比;用户手动选择要追求的方向;每选中一个职位,平台都会生成定制简历、求职信和申请邮件,这些邮件会被用户审核并发送 Gmail 草稿。防护措施也已设置:AI只使用候选人提供的信息,每个用户的数据被隔离,信用点每天免费50个,信用点在生成前显示。变现是诚实的,用户免费发现并付费获取杠杆,而不是为了列表。
我接下来会加强的内容是基于这个基础:让信用透明度更加丰富且不可错过(每次行动成本、失败生成的退款、编辑或再生的费用增加、每日50重置时),这样任何一代都不会让用户在价格上感到意外;添加明确区分确认强度与缺失或未确认要求的匹配说明,使得分成为可操作的,而非数字;使候选人提供的事实护栏在每条生成的行上清晰可见且来源清晰;通过更多门户集成扩大源库;并将申请追踪器深化为真正的流水线。持久的理念是一个求职助理,负责大规模的重复准备工作,而申请者则保留所有署名为自己名字的决定。