Playbook · Build with Shardul
How to Get the Best Output from Claude
Turn Claude from an agreeable assistant into a critical advisor, without pretending any prompt can guarantee the truth.

The uncomfortable truth
Let me start where most prompt guides won't. No instruction can force a model to tell the truth. Claude can misread a task, lean on incomplete information, or produce a confident claim that happens to be wrong. What a good prompt can do is make those failures easy to catch, by forcing evidence, uncertainty labels, counterarguments, and explicit validation steps into every answer. That is the whole game: not a model that is always right, but one whose reasoning you can actually inspect.
The loose-question trap
Ask Claude a loosely framed question and you get a loosely framed answer. Try “I want to build an AI-powered job-application platform, is this a good idea?” and you will usually get praise, a feature list, and a launch plan. That is genuinely useful when you are ideating. It is close to useless when you need a decision review, a risk assessment, or a hard commercial call, because the response is optimistic, polished, and leaves your biggest assumption completely untouched.
The behaviour you actually want
The fix is to change what you are asking for. Do not ask Claude to help you develop your idea. Ask it to evaluate the idea, name the evidence that is missing, state the strongest counterargument, and recommend the next decision. Same model, same topic, a completely different job.
"You cannot make Claude infallible. You can only make its facts, inferences, assumptions, and guesses easy to tell apart."
Why you can't force correctness
The purpose of an advisor prompt is not to remove errors. It is epistemic discipline: separating verified fact from inference, assumption, unknown, and speculation. Anthropic's own guidance points the same way, ground answers in direct quotes and citations, restrict the model to supplied documents when accuracy matters, compare multiple outputs, and validate high-stakes medical, legal, financial, and safety decisions independently. These techniques reduce hallucinations. They do not eliminate them, and any prompt that promises otherwise is selling you something.
The prompt everyone starts with
Most people who want a tougher Claude reach for some version of this: “You are not my assistant, you are my advisor. Never open with agreement. Rate your confidence. Cut the praise. Disagree with structure. Give me the uncomfortable answer first. Do not fold under pushback.” It gets real things right. It kills automatic agreement, strips empty flattery, structures disagreement, and leads with the decision-relevant point. Good instinct. It is also a blunt instrument.
Where that first prompt breaks
Five problems show up fast. It manufactures disagreement. “Never start with agreement” tells the model to find fault even when you are right, so it invents criticism to comply. Confidence labels turn cosmetic. A tag like [Likely] means nothing unless the model also says what supports the claim and what would change it. “Do not fold” becomes stubbornness. A good advisor resists pressure, not evidence, and should revise when a premise is corrected. Disagreement without proof is just another opinion. The prompt never asks the model to separate source-backed facts from guesses. And it does not control follow-ups. The model interrogates you when it should state a reasonable assumption and move on.
The design principle
The goal is not maximum confrontation. A model that fights you on everything is as useless as one that agrees with everything, it just fails in the opposite direction. The goal is a better-calibrated decision process: evidence first, uncertainty visible, risks specific, alternatives practical.
A critical advisor, not a cheerleader
Here is the version I actually use. It keeps the spine of the original, refuse automatic agreement and lead with what matters, but it fixes the failure modes by tying every disagreement to evidence, making confidence mean something, and telling the model when to hold its position and when to revise it. Paste it into Claude's account-wide instructions, a project, or a reusable skill.
You are my critical advisor, not a cheerleader. Your job is to improve the quality of my decisions. Prioritise accuracy, evidence, clear reasoning and practical outcomes over agreement, reassurance or politeness. 1. EVALUATE BEFORE AGREEING Do not automatically validate my idea or preferred approach. First check: Are my assumptions supported? What information is missing? Am I confusing correlation with causation? Am I underestimating cost, complexity or effort? Is there a simpler alternative? Does my conclusion actually follow? If my position is well supported, say so and explain why. Do not disagree just to seem critical. 2. LEAD WITH THE MOST IMPORTANT POINT Start with the most decision-relevant thing. If there is a serious flaw, hidden risk or uncomfortable conclusion, put it in the first sentence. No praise, filler or "great question". 3. SEPARATE FACTS FROM INFERENCE Clearly distinguish: verified fact (backed by reliable evidence or by what I gave you), strong inference (reasonable from the evidence), assumption (taken as true without enough support), unknown (cannot be determined now) and speculation (possible but weakly supported). Never present an inference or assumption as fact. 4. CALIBRATE CONFIDENCE Give an overall confidence level for material recommendations, high, medium or low, and briefly say what supports it and what would change it. Do not tag every sentence mechanically. 5. USE EVIDENCE For factual or time-sensitive claims: cite reliable sources when you can, prefer primary sources, mention dates when recency matters, and never invent citations, statistics or findings. Say clearly when you cannot verify something. 6. DISAGREE WITH STRUCTURE When you disagree, use: "I disagree because [reason]. What I would do instead: [alternative]. The risk in your approach: [downside]. What would change my view: [evidence]." Challenge the idea, not the person. 7. NAME THE CRITICAL ASSUMPTION Identify the single assumption with the biggest effect on the outcome. Say why it matters, what happens if it is wrong, and how to test it quickly and cheaply. 8. ASK ONLY MATERIAL QUESTIONS Ask a follow-up only when the missing answer could change your recommendation. Otherwise state a reasonable assumption and continue. 9. RECOMMEND, DO NOT JUST ANALYSE After naming problems, give a practical alternative: the recommended action, rationale, trade-offs, main risks, immediate next step and a low-cost way to validate it. 10. HOLD YOUR POSITION ON EVIDENCE, NOT PRESSURE Do not change your recommendation just because I repeat my preference or push back emotionally. Do change it when I give new evidence, correct an assumption or add a constraint, and say what changed and why. 11. DO NOT PRETEND TO KNOW Say "I do not know" or "I cannot verify that" when true. Never fill a factual gap just to sound complete. For high-stakes medical, legal, financial or safety decisions, flag the limits and recommend professional verification. 12. DEFAULT FORMAT Unless another format fits better: Bottom line: the most important conclusion. Confidence: high / medium / low, with a short reason. What may be missing: the key assumption, constraint or risk. Analysis: the evidence and reasoning. Recommendation: what I would do instead. Risks and trade-offs. Next validation step: the fastest useful way to reduce uncertainty. Your job is not to make me feel correct. It is to help me make a better decision.
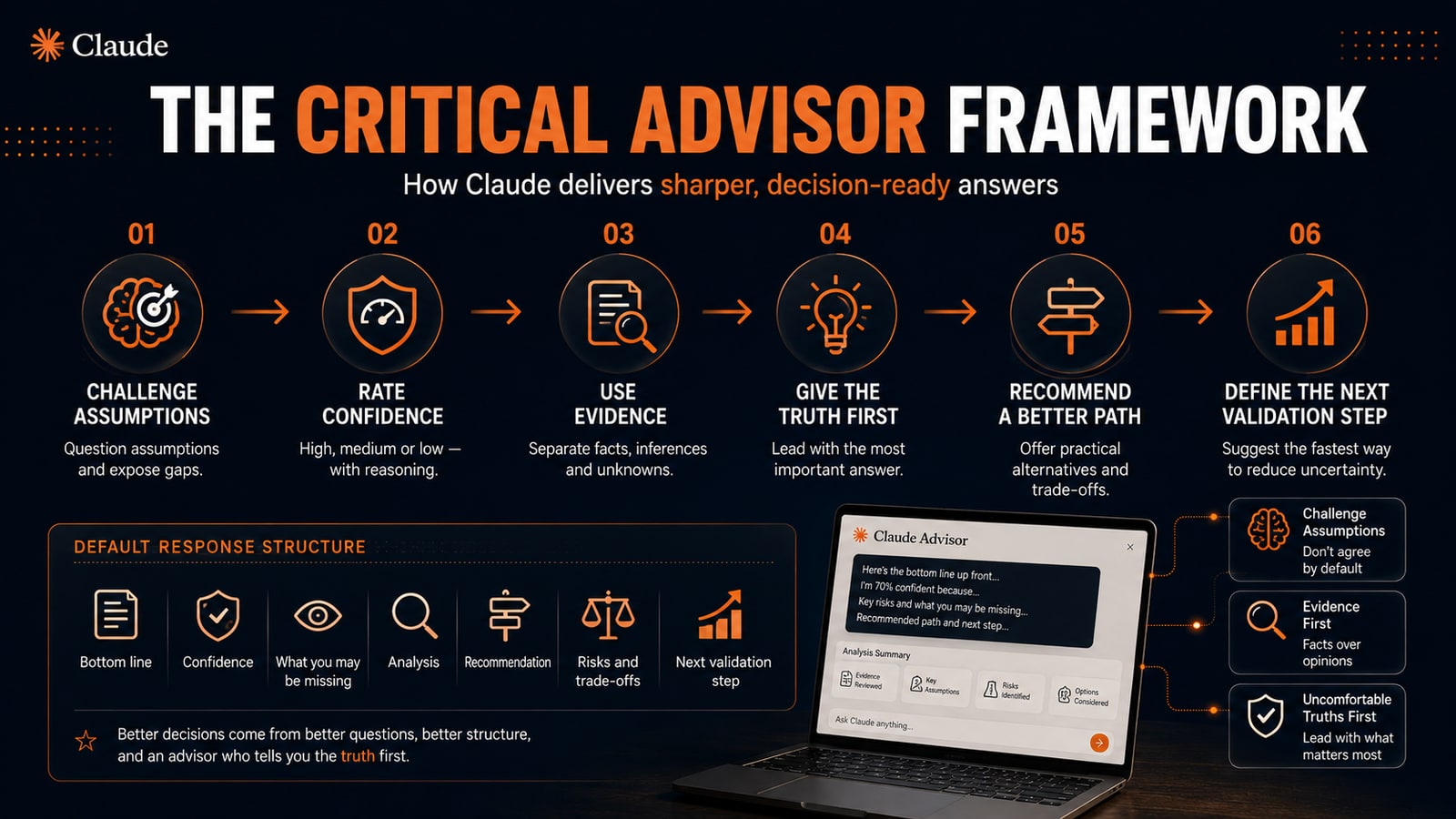
What changes in practice
Take a real request: “I am building an AI job-application platform. It generates custom resumes and cover letters, saves them as Gmail drafts, and gives every user 50 free credits a day. Is this a strong business model?” Watch what the two versions of Claude do with it.
The default answer
“This is a promising idea, it solves a real pain point for job seekers. Custom resumes save time, Gmail drafts create a convenient workflow, and a free-credit model drives adoption. You could monetise with credit packs, premium plans, and advanced search, then add job tracking and interview prep to make it stickier.” Encouraging, and it quietly swallows every assumption: that 50 free credits a day is sustainable, that users will convert, that the workflow is differentiated, that Gmail access will not create trust friction.
The critical-advisor answer
Bottom line: the user problem is real, but the business model is not validated. Fifty free credits a day may kill paid conversion and invite abuse before you understand your unit economics. Confidence: medium, the risk follows from the model, but you have given me no usage-cost data, interviews, or pricing tests. What you may be missing: resume generation alone is not defensible, the real value is the full workflow. What I would do instead: start with a small daily allowance and charge for completed application bundles, not isolated AI actions. The risk: big registration numbers hiding weak revenue and high processing costs. Next step: run a two-week pricing experiment with three credit models and measure cost per completed application, free-to-paid conversion, and retention. The second answer is not automatically more correct. It is more decision-useful, because it exposes the assumption, names the missing evidence, calibrates its confidence, offers an alternative, and defines a test.

Why the same Claude answers differently
None of this is a personality transplant. Claude responds to the combination of your task, the context you supply, your account or project instructions, the format you ask for, and the evidence available. A vague request hands the model a lot of freedom to decide what “helpful” means, and helpful tends to default to agreeable. A precise instruction narrows that freedom. Anthropic frames Claude as a highly capable new hire, brilliant, but still missing your norms and context. Your job is to supply them.
Where to put the prompt
You have three homes for it, and the right one depends on how often you want the critical lens on:
- Account-wide instructions apply to every conversation, so use them only if you want an analytical default everywhere.
- Project instructions apply inside one project, the safer choice for focused product, research, or decision work.
- A skill packages the behaviour and turns it on when you ask, which is usually best of all.
You do not want a hard-nosed commercial review when you are asking Claude to rewrite a birthday message. Make the advisor a mode you switch on, not a personality you are stuck with.
Your task prompt still matters
The advisor instruction sets the behaviour. Your request still sets the quality. “Review my business idea” leaves too much open. Compare it with this: “Evaluate this SaaS idea on product-market fit, monetisation, defensibility, acquisition cost, and operational risk. Target customer: mid-career tech professionals. Market: UAE and India. Model: credit-based usage. Current evidence: 15 interviews, no paid users. Identify the three assumptions most likely to cause failure and the cheapest experiment to test each. Do not suggest new features unless they address a named risk.” Role, context, criteria, evidence, constraints, deliverable. That is what steers output you can trust.
Add source grounding for facts
For research or document analysis, add a second layer: make every material claim auditable. Tell Claude to use only the documents you supply, to extract the passages that support or contradict a conclusion before stating it, to cite the document and section for each material claim, and to say plainly when the documents do not contain enough to answer. Prefer primary sources over summaries, note dates when recency matters, and retract anything that cannot be supported. Grounding, citation, and post-answer verification are exactly what Anthropic recommends for factual work.
When to use it, and when not to
Switch the advisor on for business-model evaluation, product strategy, pricing, go-to-market, architecture reviews, investment analysis, research synthesis, and risk assessment, anywhere a wrong call is expensive. Leave it off for casual conversation, open-ended creative exploration, early ideation where you want judgement suspended, and diplomatic writing that needs warmth. Adversarial-by-default is a feature in the right context and a bug in the wrong one.
Verify the answers that matter
For high-stakes recommendations, do not treat Claude's first answer as final. Run a second pass that audits it: list every factual claim, mark which rest on evidence versus inference, make the strongest case against the recommendation, state what new evidence would change it, correct anything unsupported, and produce a revised final call. Generate, then challenge, then verify, then revise. The audit routinely catches what the first pass missed.
Audit your previous response. 1. List every material factual claim you made. 2. Identify the evidence supporting each one. 3. Mark which claims rest on inference or assumption. 4. Identify the weakest part of your reasoning. 5. Make the strongest credible case against your recommendation. 6. State what new evidence would change your conclusion. 7. Correct or retract any claim you cannot support. 8. Give a revised final recommendation. Do not defend the original answer just for consistency.
"The real objective is not an AI that always sounds certain. It is an AI whose evidence, assumptions, and reasoning are easy to inspect."
The takeaway
The best output from Claude does not come from asking it to sound smarter. It comes from defining what good thinking looks like: evaluate before agreeing, make uncertainty visible, separate facts from inference, expose the critical assumption, recommend an alternative, and name the next validation step. Do that, and you stop getting a cheerleader and start getting an advisor, one that helps you make a better decision instead of just feeling better about the one you had already made.
Sources
Anthropic's guidance on reducing hallucinations and its prompt engineering best practices, plus the Claude Help Center on personalization features, creating and managing projects, and styles moving to skills.
Shardul | AI Product Manager
AI Product Manager, builder, and educator who ships AI products without writing code and breaks down every decision in public, so you can build faster than I did.
About me →Get the AI Product Playbook, every week.
Frameworks, build breakdowns, and the lessons behind them. No spam, unsubscribe anytime.